
Problem Statement
Searching logs for any application can be a tedious task, especially when users need to be familiar with log visualisation tools like Kibana, Sumologic, etc. These tools often have a steep learning curve, and the syntax can be confusing. We propose a solution that leverages the OpenAI API, allowing users to search logs using natural language.
For example, a user could request to see the top 10 APIs that have returned 5xx errors in the last 15 minutes.
Background
Before going into actual implementation details, I wanted to explore more about what OpenAI provides currently. So I have documented few things from OpenAI that we will be using throughout the whole journey.
OpenAI has a language model called GPT-3, which is being used to generate human-like text, answer questions, translate languages, write code, and more. The model is trained on massive amount of data to understand and generate human-like text.
How GPT works?
You can input any text as a prompt, and the OpenAI model will generate a text completion that attempts to match whatever context or pattern you give it.
E.g. When asked to “suggest movie title on developer’s life”, it said Debugged: A Comedic Tale of a Developer’s Life Funny, right? 😄😄
Now, let’s deep dive into some of the core components of GPT which we can leverage via API.
Model
OpenAI supports different models and each of these models have different objective & pricing. Some of them are listed below
GPT-3: A set of models that can understand and generate natural language
Codex: A set of models that can understand and generate code, including translating natural language to code e.g prompt to sql
Moderation: A fine-tuned model that can detect whether text may be sensitive or unsafe and complies with OpenAI’s usage policies.
A full list can be found on OpenAI docs. We will be mostly interested in codex model for this problem statement.
What is Codex Model?
The Codex models are descendants of GPT-3 models that can understand and generate code. Their training data contains both natural language and billions of lines of public code from GitHub.
We can use Codex for a variety of tasks including:
- Turn comments into code.
- Complete your next line or function in context.
- Bring knowledge to you, such as finding a useful library or API call for an application.
- Add comments to your code.
- Rewrite code for efficiency
Here is a sample prompt to generat a SQL query using completion API.
### Postgres SQL tables, with their properties: # # Employee(id, name, department_id) # Department(id, name, address) # Salary_Payments(id, employee_id, amount, date) # ### A query to list the names of the departments which employed ### more than 10 employees in the last 3 monthsOpenAI’s Response:
SELECT DISTINCT department.name FROM employee INNER JOIN department ON employee.department_id = department.id INNER JOIN salary_payments ON employee.id = salary_payments.employee_id WHERE salary_payments.date >= (CURRENT_DATE - INTERVAL '3 months') GROUP BY department.name HAVING COUNT(employee.id) > 10
Completion API
All these functionalities are available through completion API. Given a prompt, the model will return one or more predicted completions.
Sample curl,
curl https://api.openai.com/v1/completions \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"model": "code-davinci-002",
"prompt": "Create query to find users with age greater than 30",
"max_tokens": 7,
"temperature": 0
}'
Let’s understand what these each of these body params means:
model:code-davinci-002orcode-cushman-001for code completion.prompt: user prompt that user will provide.temperature: Higher values means the model will take more risks. Try0.9for more creative applications, and0(argmax sampling) for ones with a well-defined answer.max_tokens: The maximum number of tokens to generate in the completion.
Training Model for specific use cases
For any specific use case, it’s also possible to train model on top of any existing base model by providing example datasets to model.
Data needs to be a JSONL document, where each line is a prompt-completion pair corresponding to a training example. Once we provide these datasets with custom model name, we can use it just like any other model
Example dataset:
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
...
Solution
Since now we have explored different components of OpenAI API’s, let’s talk about how can we use this for our orignial problem statement. For developing a log explorer POC, we will only be focusing on searching logs from Kibana.
Approach 1
- We can make use of prompt to SQL code completion feature from OpenAI.
- Elastic search provides APIs to fetch all fields names with data types for all indices which are logged in given time frame.
- We will use field names & data types from ES to define schema for OpenAI SQL completion API.
- Elastic search provides a SQL feature to execute SQL queries against Elasticsearch indices and return results in tabular format. We can use SQL returned from OpenAI to execute it on ES.
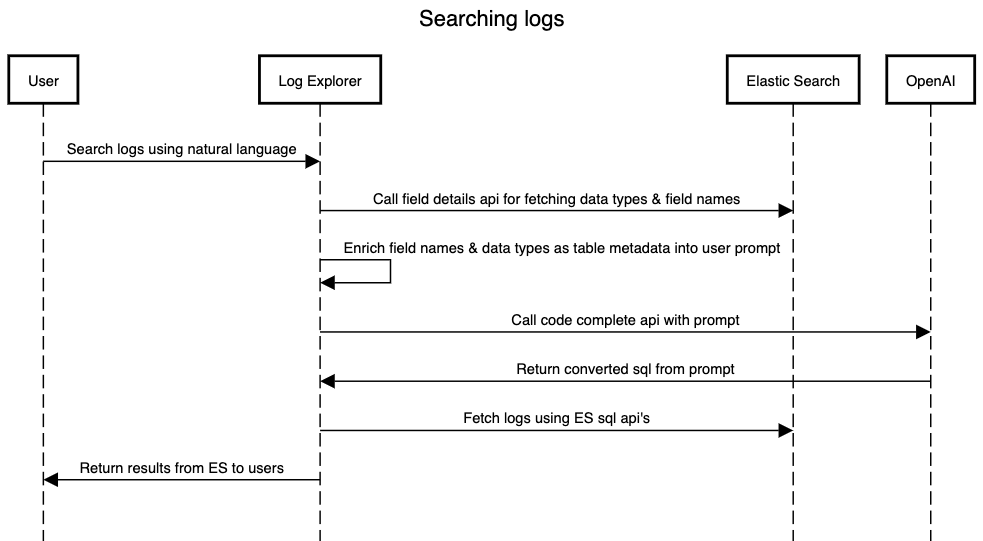
Example:
User Prompt
A query to list logs having 5xx error
Input for OpenAI
### Postgres SQL tables, with their properties:
# logs_table[message, msg, level, RequestHeaders.user_id, RequestHeaders.user_type, RequestMethod, RequestProxy, RequestTime, RequestURL, ResponseStatus(int), ResponseTime, time]
### A query to list logs having 5xx error
Query Returned by OpenAI
SELECT * FROM logs_table WHERE ResponseStatus >= 500 AND ResponseStatus < 600
So far, we examined the overall concept of using OpenAI to search logs via natural language. Specifically, we looked at the different models and capabilities that OpenAI offers, with a focus on the Codex model and the code completion API.
We also touched on the idea of fine-tuning the model for specific use cases by providing example datasets.
In our next part for this series, we will delve deeper into the code completion API of GPT to determine its feasibility for our specific use case. Stay tuned for more updates on this exciting project!